Расширения GCC: Как использовать атрибуты выравнивания
Атрибуты выравнивания в основном используются при выделении памяти для структур данных, которые содержат в себе "разношерстные" типы по своему размеру или длине, часто называемой размерностью типов. Так же использование таких атрибутов позволяет избежать разрыва последовательности бинарного кода и целостности данных в операциях чтения и записи из-за неверного определения размера получаемых данных, как показано в листинге 1.
|
Листинг 1 typedef unsigned char ubyte_t; /* размер: 1 байт */ typedef unsigned short word_t; /* размер: 2 байта (слово)*/ typedef unsigned int word_t; /* размер: 4 байта (двойное слово).*/ /* Определение структурного типа foo_item */ struct foo_item { ubyte_t byte; /* 1 байт + 1 "лишний" байт */ uword_t word; /* 2 байта */ udword_t udword; /* 4 байта */ }; /* Итого: общий размер 7 байт + 1 "лишний" байт */ typedef struct foo_item foo_item_t; /* Псевдоним struct foo_item */ #define FOO_NITEMS 9 /*Кол-во влож. стурктур foo_item */ /* Структурный тип данных foo */ struct foo { ubyte_t byte; /* 0, 1, 2, 3, bytes (3 added bytes) */ udword_t udword; /* 4, 5, 6, 7, bytes */ foo_item_t items[FOO_NITEMS]; /* 8, ... ,79 bytes */ }; /* Имеет длину 80 байт (в т.ч. 3 "лишних" байта без учета в массиве items накопленного мусора размером 9 байт)*/ struct foo foo1; /* Выделение памяти для структурного тип данных foo по адресу переменной foo1 */ |
На рис.2 показаны последствия принебрежением выравнивания структуры данных foo и "вложенного" в него массива структур с псевдонимом foo_item_t. При этом, на первый взгляд, происходит "чудесное" превращение потока данных, состоящего из 68 байт (приведен на рис. 1), в упорядоченный структурированный массив данных, содержащий уже 80 байт. Данный результат будет одинаков после выполнения кода, приведенного в листинге 1, как на 32-х, так и на 64-х разрядной архитектуре, так как меняющие свою размерность типы данных от её разрядности здесь не используются.
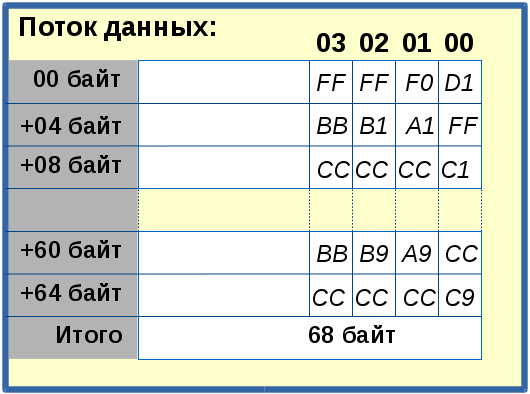
Рис. 1 |

Рис. 2 |
Как следствие, на рис. 2 приходиться наблюдать так называемые "дырки", выделенные красным нулевые значения. Причина их появления кроется в дополнении размерности однобайтовых членов структур до соседних, имеющие длину два и более байт, что неизбежно влечет за собой разрыв последовательности бинарного кода и целостности данных при выполнении операций чтения или записи.
Для исправления ситуации, методом "штопки" структурированного массива данных, попробуем убрать "дырки" последовательно используя атрибуты выравнивания __packed__ и aligned.
Первым, используем атрибут __packed__ при определении структурного типа с псевдонимом foo_item_nonaligned_t, как показано в Листинге 2.
|
Листинг 2 typedef struct { ubyte_t byte; /* 0, байт */ udword_t udword; /* 1, 2, 3, 4, байт */ foo_item_t items[FOO_NITEMS]; /* 5, ... ,76 байт */ } __attribute__ ((__packed__)) foo_item_nonaligned_t; /* Имеет длину 77 байт без учета накопленного 9 байт мусора в однобайтовых полях массива items */ foo_item_nonaligned_t foo2; /* Выделение памяти для структурного типа данных с псевдонимом foo_item_nonaligned_t по адресу переменной foo2 */ |
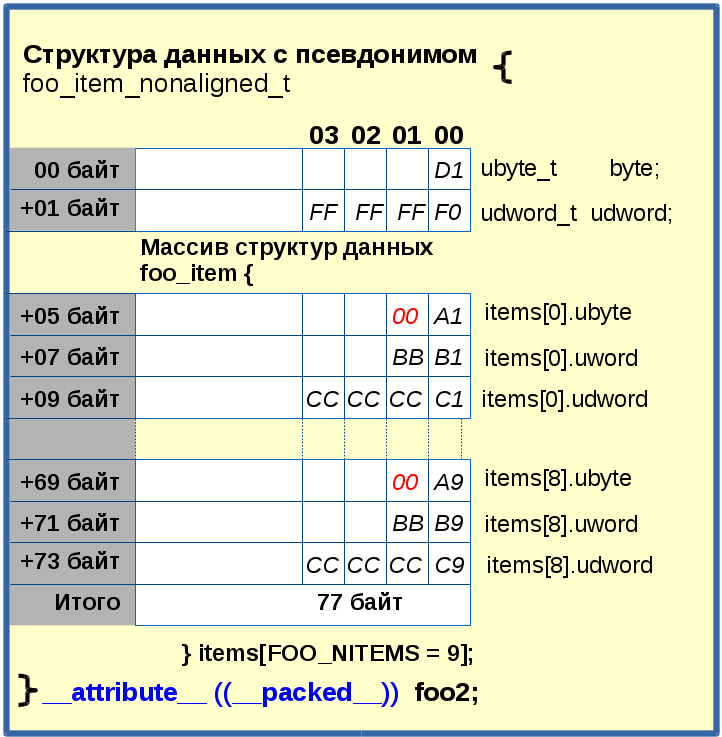
Рис. 3 |
Как видно из рис. 3, использование атрибута __packed__ явно недостаточно для выравнивания структуры данных, выделенной в памяти по адресу foo2, при наличии в ней вложенного массива структур данных. Поэтому наряду с ним, как показано в листинге 4, задействуется атрибут aligned для выравнивания структуры c псевдонимом foo_item_aligned_t.
|
Листинг 4 typedef struct { ubyte_t ubyte; /* 0 байт*/ uword_t uword __attribute__((__packed__)); /* 1, 2,байт*/ udword_t udword __attribute__((__packed__));/* 3, 4, 5, 6 байт*/ } __attribute__ ((aligned(1))) foo_item_aligned_t; /* Длина 7 байт */ typedef struct { ubyte_t byte; /* 0, байт */ udword_t udword; /* 1, 2, 3, 4, байт */ foo_item_aligned_t items[FOO_NITEMS]; /* 5, ... ,67 байт */ } __attribute__ ((__packed__)) foo_aligned_t; foo_aligned_t foo3; /* Имеет длину 68 байт без какого-либо мусора в однобайтовых полях */ |
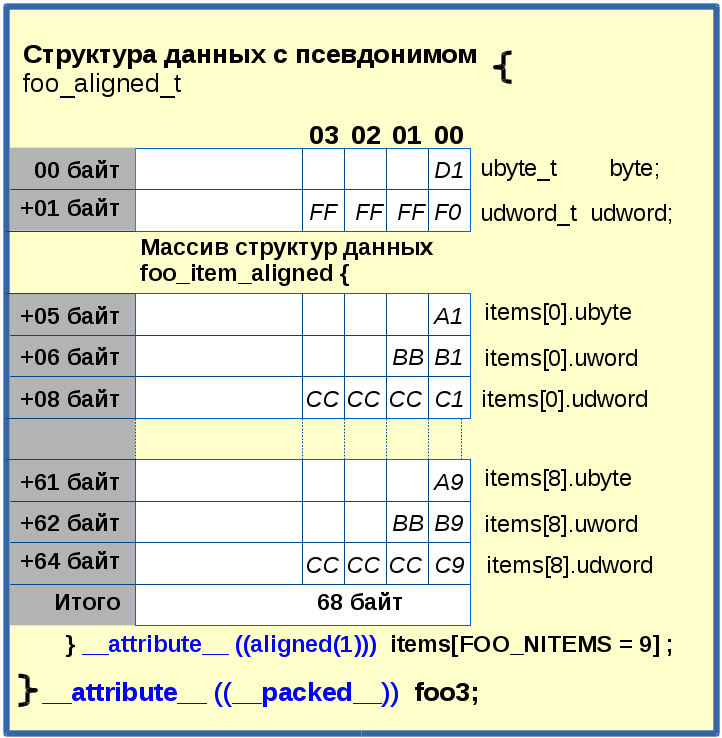
Рис. 4 |
Таким образом, комбинируя атрибутами выравнивания __packed__ и aligned, удалось добиться нужного результата, приведенного на рис.4. Структурированный массив данных не имеет нарушений целостности, соблюдена неразрывность бинарного кода, что подтверждается отсутствием "дырок". Таким образом, длинна и порядок следования в нем значений полностью соответствует потоку данных, приведенного на рис.1.